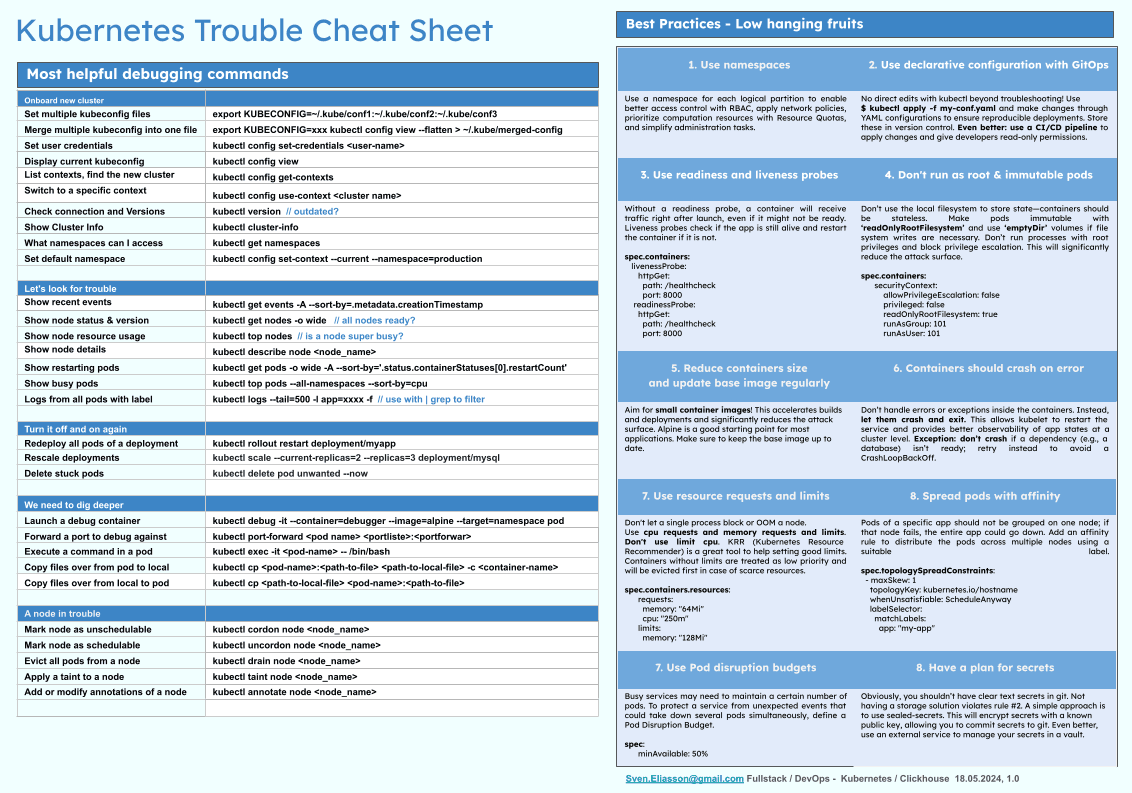
2.5x Performance: PostgreSQL to Clickhouse without Kafka with MaterializedPostgreSQL
TimeSeries Expert Full stack, DevOps Kubernetes, Clickhouse DB
TLDR: Stream PostgreSQL data to ClickHouse without Kafka using MaterializedPostgreSQL for real-time data replication and optimization, achieving significant data compression and query 2.5x performance improvements.
Dealing with billions of sensor records, as we do at Rysta, is no easy task. We encountered challenges in maintaining the performance of some of our analytical workloads within PostgreSQL. PostgreSQL has been exceptional for us, and I suggest that anyone handling analytical tasks (OLAP) should start with PostgreSQL, specifically TimescaleDB.
However, for numerous analytical queries, PostgreSQL's row-based storage is slower compared to columnar storage used in many OLAP databases. After exploring various analytical database choices, I fell in love with ClickHouse. It excites me daily, and I started creating prototypes using ClickHouse, which delivered exceptional performance.
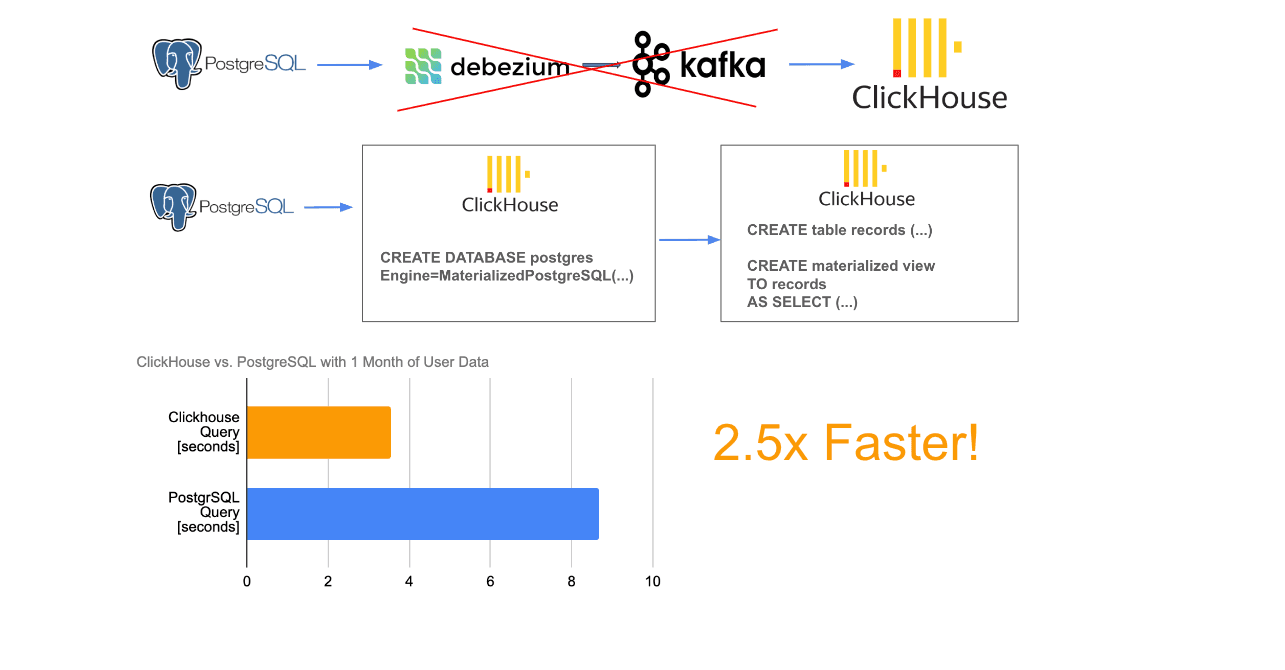
Currently, we store all our sensor records in a PostgreSQL database, and we have no plans to change this setup soon. Hence, we aim to replicate data from PostgreSQL to ClickHouse in real-time to power certain analytical workloads. A common method involves using CDC with Debezium/Kafka, as explained in this blog post. While this is a reliable and proven method, we do not utilize a Kafka cluster right now, and I prefer to avoid the extra work that comes with it. So, why not stream data directly into ClickHouse without an intermediary data broker? This is precisely achievable with ClickHouse's experimental feature called MaterializedPostgreSQL.

MaterializedPostgreSQL allows you to set up a ClickHouse database from a distant PostgreSQL database. Once an initial data snapshot is taken, modifications are copied using PostgreSQL's WAL. As of now, this feature is still experimental, but it has worked perfectly for us until this point.
SET allow_experimental_database_materialized_postgresql=1;
CREATE DATABASE postgres
ENGINE = MaterializedPostgreSQL('host:port', 'database', 'user', 'password')
SETTINGS materialized_postgresql_schema = 'myschema';
We used this approach to sync a sample dataset of about a billion records in about 5 minutes, which amazed me! The initial prototypes used a batch-wise ETL process that took over an hour for the first data sync. So already a good start! The table is automatically updated as new data is inserted into PostgreSQL.
Now that we have the date in our clickhouse cluster we could start using it... but it would probably not be faster than using a postgreSQL replica.
select sum(bytes_on_disk) FROM system.parts where database = 'postgres'
/ 21841081469
The sample dataset uses around 20GB of data for a billion records. Let's utilize ClickHouse's specific features to optimize this dataset for quicker query performance:
Use codecs to compress the physical data size; smaller datasets are often faster to query.
Utilize a sparse index to reduce the number of chunks that need to be scanned line by line.
Implement a partition that will divide the table based on a pattern optimized for the queries we intend to execute.
There are trade-offs to consider, and the table structure should be fine-tuned based on your most crucial queries. The table DDL that proved to be most efficient was:
CREATE TABLE mydb.records (
value Float32 CODEC(Gorilla),
t DateTime CODEC(DoubleDelta),
sensor_id UInt32 CODEC(T64)
) ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMM(t)
ORDER BY (toStartOfHour(t), sensor_value_id, t)
PRIMARY KEY ( toStartOfHour(t), sensor_value_id);
Now that we have the perfect table, how do we populate it with data? I could insert data from the Postgres database into my ClickHouse-native table using an insert query, but this would have to be done for every insertion into the Postgres table. This is where we can make use of ClickHouse's "Materialized view," which functions differently compared to other databases like PostgreSQL. It's more like a trigger that runs a query on a specific table every time data is inserted into the source table.
CREATE MATERIALIZED VIEW mydb.records_mv
TO mydb.records
AS
SELECT
data as value,
timestamp as t,
sensor_id as sensor_id
FROM postgres.records;
After running this query, whenever new data is added to the PostgreSQL table, it will also be inserted into our ClickHouse-native, optimized table. This process only adds new records. However, we can initially copy over a snapshot like this:
INSERT INTO mydb.sensor_value_record
SELECT
data as value,
timestamp as t,
sensor_id as sensor_id
FROM postgres.records
Voila! The resulting table compressed the initial 20GB into 3.9GB, achieving an 87% compression.
So that's it? Basically yes.
So everything is great? Not exactly...
CREATE MATERIALIZED VIEW mydb.records_mv_2024_04
TO mydb.records
AS SELECT data as value, timestamp as t, sensor_id as sensor_id
FROM postgres.records_2024_04;
CREATE MATERIALIZED VIEW mydb.records_mv_2024_05
TO mydb.records
AS SELECT data as value, timestamp as t, sensor_id as sensor_id
FROM postgres.records_2024_05;
CREATE MATERIALIZED VIEW mydb.records_mv_2024_06
TO mydb.records
AS SELECT data as value, timestamp as t, sensor_id as sensor_id
FROM postgres.records_2024_06;
... and so on
I hope there will be native support for partitions in MaterializedPostgreSQL. However, from my research, it seems that this support is not actively being worked on or planned at the moment.
So, this is how we currently execute a prototype for particular analytical tasks, and it has been successful. In a specific slow query (retrieving all sensor data of a user in a given month), we noticed a 2.5x performance improvement!

If you have any questions, feel free to email me at sven.eliasson-at-gmail.com